




Генеративные модели ИИ уже сегодня способны выполнять прикладные задачи нефтегазовой отрасли. Компании ТЭК приступили к пилотированию технологий на базе LLM. Однако в масштабах отрасли из-за сепаратного подхода к таким проектам происходит неэффективное дублирование усилий и средств. Почему российский нефтегаз не хочет кооперироваться для создания универсальных решений? Какой набор компетенций и ресурсов нужен отраслевым игрокам для разработки и поддержки GenAI-приложений? Об этом рассказывает управляющий директор «Выгон Консалтинг» Григорий Выгон.
CNews: Для каких задач сегодня и в перспективе можно применять LLM в нефтегазовых компаниях?
Григорий Выгон: Недавно совместно с «Газпром нефтью» мы проанализировали спектр инженерных задач, потенциально решаемых с помощью GenAI. В результате получили список доступных решений на базе LLM для использования в производственных процессах нефтегазовых компаний. Во-первых, это трансформация данных. Например, распознавание различных многочисленных неструктурированных источников информации (геологических отчетов, паспортов оборудования, нормативно-методической документации) и извлечение из них структурированных данных (базы данных, графы знаний, каталоги и т.д.). На их основе можно быстрее и качественней подбирать месторождения-аналоги и технико-экономические параметры для проектов обустройства и разработки.
Во-вторых, LLM могут выполнять функции ассистентов инженеров. В случае с нефтедобывающим оборудованием такие приложения создаются на основе отраслевой документации - ГОСТов, регламентов, руководств по эксплуатации, ремонтных журналов, патентов, научно-технических статьей и т.д. В результате технолог получит помощника по анализу и предотвращению причин поломок оборудования, рекомендации по их устранению. А также сможет эффективнее подобрать методы борьбы с осложнениями механизированной добычи.
В перспективе, с созданием AGI (artificial general intelligence), модели помогут в проектировании, разработке новых технологий, материалов и оборудования, а также в интегрированном управлении производством – в том числе путем взаимодействия с внешним ПО и роботизированными системами.
Во-вторых, LLM могут выполнять функции ассистентов инженеров. В случае с нефтедобывающим оборудованием такие приложения создаются на основе отраслевой документации - ГОСТов, регламентов, руководств по эксплуатации, ремонтных журналов, патентов, научно-технических статьей и т.д. В результате технолог получит помощника по анализу и предотвращению причин поломок оборудования, рекомендации по их устранению. А также сможет эффективнее подобрать методы борьбы с осложнениями механизированной добычи.
В перспективе, с созданием AGI (artificial general intelligence), модели помогут в проектировании, разработке новых технологий, материалов и оборудования, а также в интегрированном управлении производством – в том числе путем взаимодействия с внешним ПО и роботизированными системами.
CNews: В чем проблемы использования LLM в нефтегазовом секторе?
Григорий Выгон: Недостатки так называемых базовых LLM для бизнес-задач хорошо известны. Это неточность ответов – вплоть до галлюцинаций, низкая верифицируемость, недостаточная актуальность, невысокие способности к сложным рассуждениям (reasoning).
Базовым LLM также сегодня сильно не хватает знаний и навыков для решения узкоспециализированных прикладных задач. Хотя лучшие коммерческие зарубежные LLM уже неплохо ориентируются в отраслевых доменах, поскольку практически все данные из открытых источников содержатся в корпусе моделей для исходного обучения (pre-train). Однако российским нефтегазовым компаниям их нельзя использовать из-за санкций и вопросов информационной безопасности.
Отечественные же модели – Yandex GPT и GigaChat – пока уступают по многим бенчмаркам на английском и русском языках как коммерческим LLM, так и моделям с открытыми весами. Основная причина в том, что для их тренировки использовалось меньшее количество вычислительных ресурсов и объем тренировочных датасетов. Кроме того, их веса закрыты, а доступ через API несколько сложнее, чем у большинства вендоров и пока недостаточно задокументирован.
Базовым LLM также сегодня сильно не хватает знаний и навыков для решения узкоспециализированных прикладных задач. Хотя лучшие коммерческие зарубежные LLM уже неплохо ориентируются в отраслевых доменах, поскольку практически все данные из открытых источников содержатся в корпусе моделей для исходного обучения (pre-train). Однако российским нефтегазовым компаниям их нельзя использовать из-за санкций и вопросов информационной безопасности.
Отечественные же модели – Yandex GPT и GigaChat – пока уступают по многим бенчмаркам на английском и русском языках как коммерческим LLM, так и моделям с открытыми весами. Основная причина в том, что для их тренировки использовалось меньшее количество вычислительных ресурсов и объем тренировочных датасетов. Кроме того, их веса закрыты, а доступ через API несколько сложнее, чем у большинства вендоров и пока недостаточно задокументирован.
CNews: Как нужно дорабатывать существующие сегодня ИИ-решения, чтобы адаптировать их к выполнению отраслевых задач?
Григорий Выгон: Совершенствование решений на базе LLM нужно проводить последовательно по нескольким основным направлениям: предобработка данных, промпт-инжиниринг, RAG (retrieval augmented generation) и дообучение (fine tuning).
Самый простой и дешевый способ повысить качество ответов LLM – промпт-инжиниринг. С RAG все сложнее, но интереснее. Ассистенты и вопросно-ответные системы, как правило, создаются на основе этой технологии. В отличие от базовых LLM, они позволяют находить актуальную информацию в специализированных и внутренних корпоративных документах, чтобы генерировать максимально точный ответ.
Чтобы система эффективно работала, необходимо подбирать, настраивать и оценивать все элементы пайплайна RAG: препроцессинг данных, извлечение релевантных фрагментов, дополнение контекста и генерацию ответа. Расшивка узких мест в этой цепочке для повышения качества ответа происходит в ходе кропотливого тестирования и оценки результатов работы каждого ее элемента и RAG в целом. Все это - область серьезного R&D, по ней ежедневно выходит множество научных и прикладных исследований. Добиться точности ответа выше 80% на запросы к большой базе документов с неструктурированной информацией – это определенный вызов для разработчиков приложений на базе LLM.
Самый простой и дешевый способ повысить качество ответов LLM – промпт-инжиниринг. С RAG все сложнее, но интереснее. Ассистенты и вопросно-ответные системы, как правило, создаются на основе этой технологии. В отличие от базовых LLM, они позволяют находить актуальную информацию в специализированных и внутренних корпоративных документах, чтобы генерировать максимально точный ответ.
Чтобы система эффективно работала, необходимо подбирать, настраивать и оценивать все элементы пайплайна RAG: препроцессинг данных, извлечение релевантных фрагментов, дополнение контекста и генерацию ответа. Расшивка узких мест в этой цепочке для повышения качества ответа происходит в ходе кропотливого тестирования и оценки результатов работы каждого ее элемента и RAG в целом. Все это - область серьезного R&D, по ней ежедневно выходит множество научных и прикладных исследований. Добиться точности ответа выше 80% на запросы к большой базе документов с неструктурированной информацией – это определенный вызов для разработчиков приложений на базе LLM.
Что касается дообучения, то оно требует более значительных вычислительных ресурсов и трудозатрат для подготовки больших датасетов, тренировки и тестирования. Учитывая, что в нефтегазовом домене есть множество подобластей, сбор соответствующих данных без привязки к конкретным задачам выглядит неэффективной тратой времени. Кроме того, в процессе дообучения меняются исходные веса модели, что может приводить к потере предыдущих знаний (так называемый эффект «катастрофического забывания»).
Для узкопрофильных задач донастройка действительно повышает качество ответов, но с нее точно не нужно начинать, по крайней мере в вопросно-ответных системах, где хватает своих узких мест в технологии RAG. Значительно повысить качество ретривера (поиска релевантных фрагментов текста) может помочь дообучение отраслевой специфике небольшой модели-энкодера, которая используется для векторизации текстовых фрагментов и запросов пользователя.
Для узкопрофильных задач донастройка действительно повышает качество ответов, но с нее точно не нужно начинать, по крайней мере в вопросно-ответных системах, где хватает своих узких мест в технологии RAG. Значительно повысить качество ретривера (поиска релевантных фрагментов текста) может помочь дообучение отраслевой специфике небольшой модели-энкодера, которая используется для векторизации текстовых фрагментов и запросов пользователя.
CNews: Как российские нефтегазовые компании сегодня пытаются использовать LLM?
Григорий Выгон: Технология новая, нефтегазовые компании только с прошлого года запускают пилотные решения. Как и следовало ожидать, они в основном фокусируются на вопросно-ответных системах в разных областях – HR, финансы, внутренние нормативные документы, геологические отчеты и т.д. Так, «Татнефть» совместно с ИТМО на базе Llama 2 сделала «Акелу» – прототип по подготовке к внутреннему экзамену по промышленной безопасности.
«Сибур» объявил о создании совместно со «Сбером» на базе GigaChat прототипов AI-ассистента инженера-диагноста и AI-советчика для оптимизации закупки материально-технических ресурсов. Компания планирует разработку AI-помощника в R&D-направлении для моделирования полимеров и создания материалов с новыми свойствами, а также AI-ассистента финансиста.
«Газпром нефть», насколько нам известно, сегодня реализует несколько пилотных проектов, в том числе достаточно сложных. Возможно, в свое время компания о них расскажет.
«Сибур» объявил о создании совместно со «Сбером» на базе GigaChat прототипов AI-ассистента инженера-диагноста и AI-советчика для оптимизации закупки материально-технических ресурсов. Компания планирует разработку AI-помощника в R&D-направлении для моделирования полимеров и создания материалов с новыми свойствами, а также AI-ассистента финансиста.
«Газпром нефть», насколько нам известно, сегодня реализует несколько пилотных проектов, в том числе достаточно сложных. Возможно, в свое время компания о них расскажет.
CNews: Подозреваю, что у нефтегазовых инженеров из разных компаний есть набор очень похожих задач, для которых можно использовать универсальные общеотраслевые LLM-решения.
Григорий Выгон: Да, действительно, некоторые задачи, сепаратно решаемые разными компаниями, уже пересекаются. По сути, происходит ненужное дублирование усилий и средств. Мы изучили возможности GenAI для создания таких универсальных решений, разработав MVP «Ассистент геолога» и «Ассистент по работе с нефтегазовом оборудованием». Это во многом похоже на то, что делают «СИБУР» и «Газпром нефть».
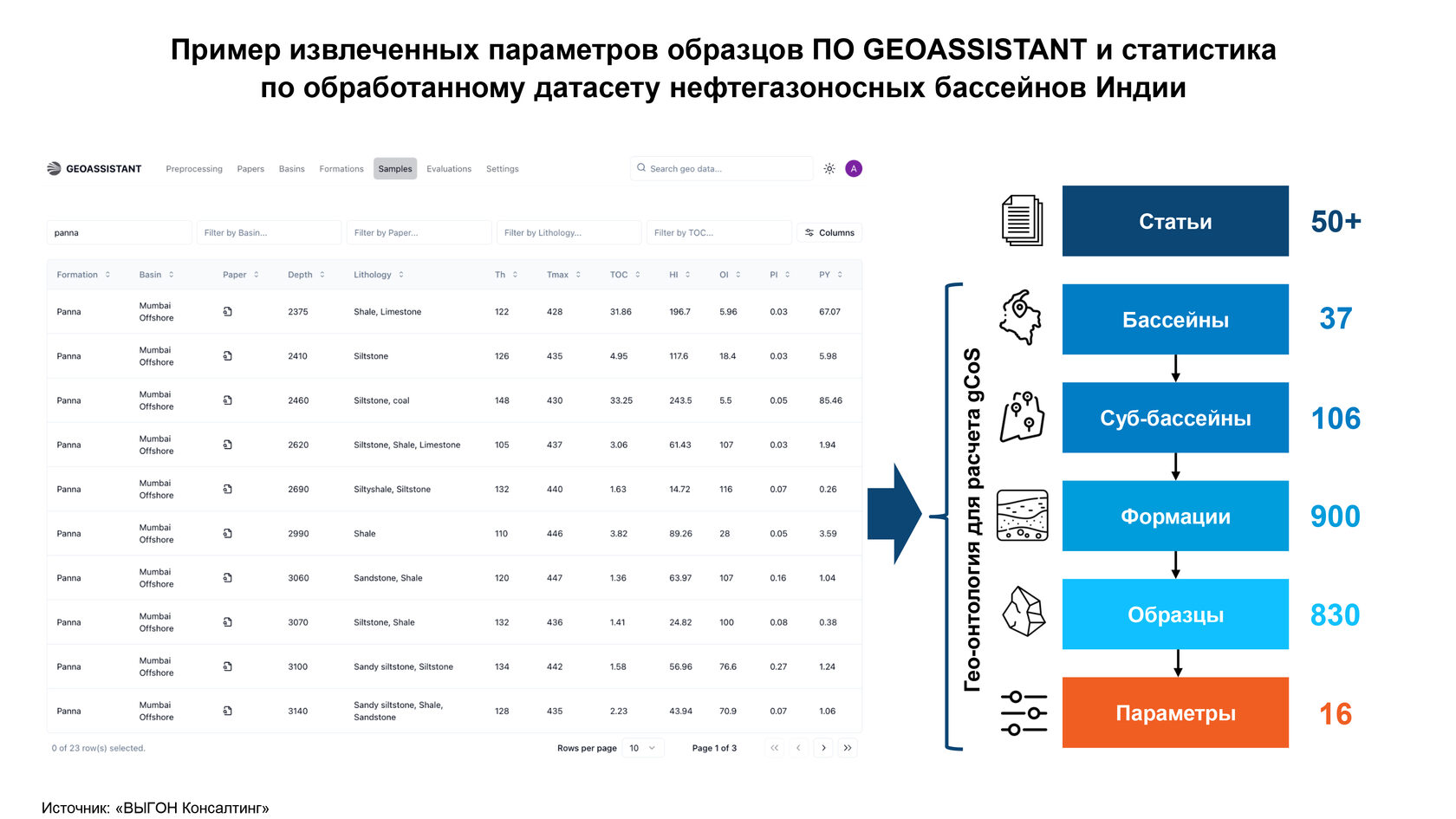
При этом в «Ассистенте геолога» мы дополнительно тестировали возможность извлечения информации из неструктурированных документов - геологических отчетов. Эти данные необходимы для оценки gCoS (geological chance of success - шанса геологического успеха), или, проще говоря, вероятности открытия месторождения углеводородов. Такое решение на базе LLM значительно сокращает временные затраты геологов на поиск и анализ данных, а также повышает объективность оценки. Например, в России инструмент для оценки gCoS на базе LLM может быть очень полезен нефтегазовым компаниям, работающим в новых слабо изученных регионах, где сохраняется значительный потенциал по крупным открытиям.
При этом в «Ассистенте геолога» мы дополнительно тестировали возможность извлечения информации из неструктурированных документов - геологических отчетов. Эти данные необходимы для оценки gCoS (geological chance of success - шанса геологического успеха), или, проще говоря, вероятности открытия месторождения углеводородов. Такое решение на базе LLM значительно сокращает временные затраты геологов на поиск и анализ данных, а также повышает объективность оценки. Например, в России инструмент для оценки gCoS на базе LLM может быть очень полезен нефтегазовым компаниям, работающим в новых слабо изученных регионах, где сохраняется значительный потенциал по крупным открытиям.
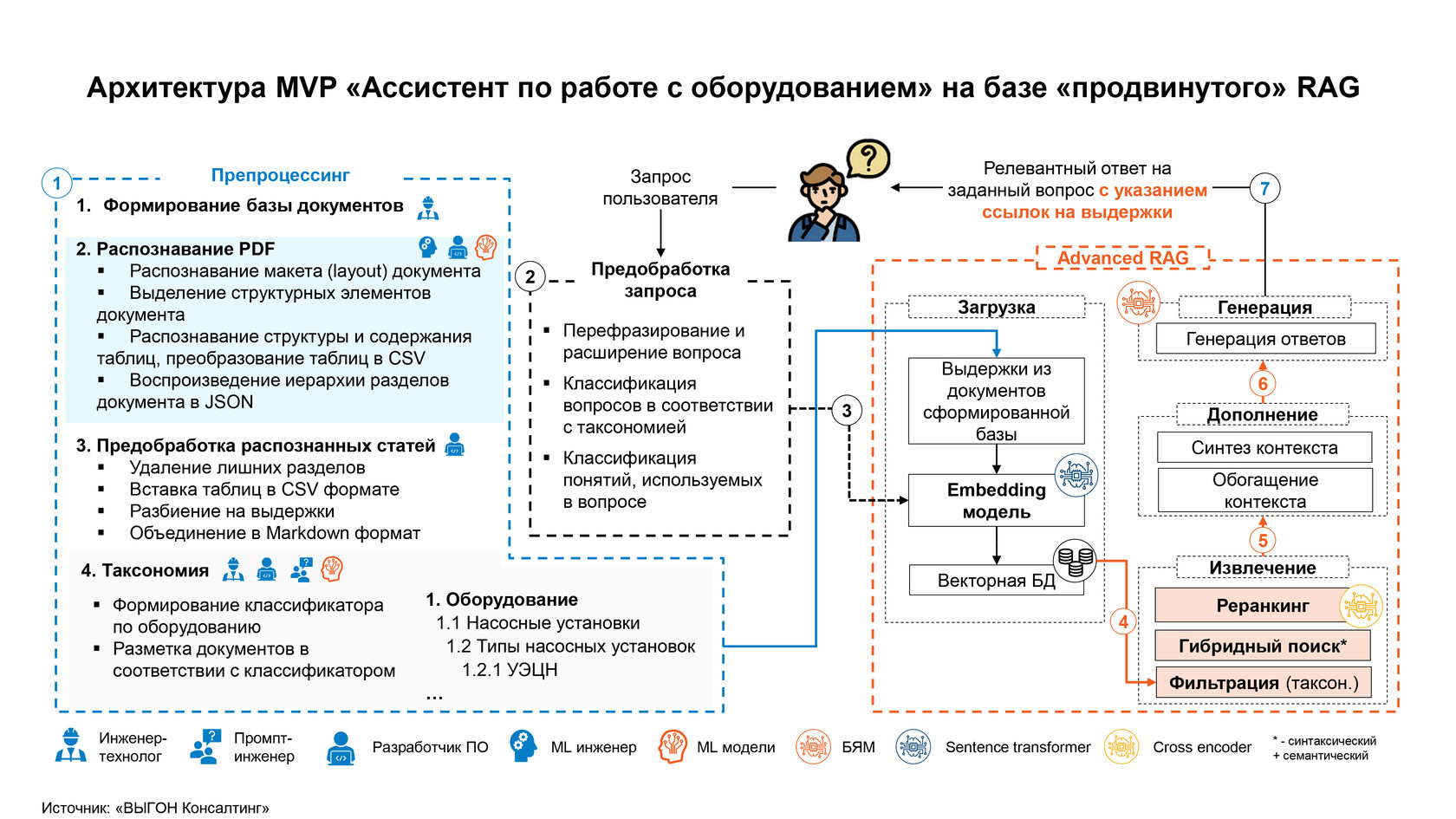
«Ассистент по работе с оборудованием» – диалоговая система с использованием «продвинутого» RAG, способная предоставлять специалистам различных направлений нефтегазовой отрасли релевантные ответы на вопросы с указанием первоисточника. Границы ее применения широки: подбор оборудования под конкретные условия эксплуатации, анализ и профилактики его поломок и т.д. Очевидно, подобная система будет полезна не только в нефтегазе, но и в других отраслях промышленности. При этом архитектура может быть универсальной, отличаться будет лишь база знаний.
CNews: Возможна общеотраслевая консолидация для создания универсальных LLM-решений? И что мешает нашим нефтегазовым компаниям это сделать?
Григорий Выгон: Одним из форматов отраслевой кооперации является создание платформы, объединяющей ресурсы, инфраструктуру и компетенции для решения общеотраслевых задач. Это позволит диверсифицировать риски, в том числе в области кибербезопасности, уменьшить неэффективные расходы на дублирование усилий и нарастить компетенции.
Однако, как показало наше общение с отраслевыми игроками, основным барьером в создании платформы стал обмен информацией. Компании напряженно относятся к раскрытию данных, даже не имеющих конфиденциальный характер.
Для решения некоторых задач одних внутренних данных недостаточно в силу редкости наступления определенных событий. Например, это относится к анализу причин поломок оборудований. Эту проблему можно решить с помощью синтезирования данных. Существуют и другие способы наладить обмен информации между компаниями без раскрытия конфиденциальных сведений - федеративное обучение, confidential computing.
Очевидно, компании должны созреть для кооперации, а для этого им необходимо пройти определенный путь в области создания пилотных приложений на базе LLM.
Однако, как показало наше общение с отраслевыми игроками, основным барьером в создании платформы стал обмен информацией. Компании напряженно относятся к раскрытию данных, даже не имеющих конфиденциальный характер.
Для решения некоторых задач одних внутренних данных недостаточно в силу редкости наступления определенных событий. Например, это относится к анализу причин поломок оборудований. Эту проблему можно решить с помощью синтезирования данных. Существуют и другие способы наладить обмен информации между компаниями без раскрытия конфиденциальных сведений - федеративное обучение, confidential computing.
Очевидно, компании должны созреть для кооперации, а для этого им необходимо пройти определенный путь в области создания пилотных приложений на базе LLM.
CNews: Что сегодня нужно для разработки LLM-решений в нефтегазовой компании?
Григорий Выгон: Для начала следует приоритезировать задачи, которые можно решать на базе LLM. Критериями выбора «пилотов» являются добавленная стоимость от их внедрения и принципиальная реализуемость решений с учетом уровня развития технологии. При этом нужна заинтересованность и плотная кооперация цифрового блока и внутренних бизнес-функций. Как и с любой трансформацией процессов, нужно преодолеть внутреннее сопротивление консервативных сотрудников.
Сегодня сфера GenAI одна из самых быстро развивающихся. Ежемесячно выходят релизы более десятка крупных и всё более совершенных языковых моделей, публикуются сотни статей по новым методам обучения, дообучения, донастройки, RAG, промт-инжиниринга, тестирования и оценки (evaluation), мышления (reasoning) и т.п. Невозможно полноценно совмещать основную работу - например, геолога в нефтегазовой компании - и участие в исследованиях и разработке приложений на базе LLM. Поэтому необходимо привлечь квалифицированных подрядчиков.
Сегодня сфера GenAI одна из самых быстро развивающихся. Ежемесячно выходят релизы более десятка крупных и всё более совершенных языковых моделей, публикуются сотни статей по новым методам обучения, дообучения, донастройки, RAG, промт-инжиниринга, тестирования и оценки (evaluation), мышления (reasoning) и т.п. Невозможно полноценно совмещать основную работу - например, геолога в нефтегазовой компании - и участие в исследованиях и разработке приложений на базе LLM. Поэтому необходимо привлечь квалифицированных подрядчиков.
CNews: Наши российские бигтехи способны закрыть потребности нефтегаза в качественных LLM-решениях?
Григорий Выгон: В бигтехах – «Сбере» и «Яндексе» – собраны сильные команды ML-инженеров, которые занимаются обучением базовых моделей. Однако они не имеют отраслевых знаний в конкретных доменах, поэтому дообучить свои модели для решения прикладных задач самостоятельно они не смогут. Не исключено, что они будут продвигать решения на основе своих базовых моделей, которые пока отстают не только от лидирующих коммерческих, но и от опенсорсных (Llama, Mistral, Qwen и т.д.). Здесь им на помощь как раз и придут внешние отраслевые консультанты и специализированные лаборатории.
Каждая компания выберет свой подход по разработке и внедрению решений на базе GenAI в части приоритизации задач и выбора партнеров. Однако принципиальным является максимально быстрое вовлечение в этот процесс, иначе технологическое отставание от западных и восточных конкурентов, активно внедряющих языковые модели в свой бизнес, будет нарастать.
Каждая компания выберет свой подход по разработке и внедрению решений на базе GenAI в части приоритизации задач и выбора партнеров. Однако принципиальным является максимально быстрое вовлечение в этот процесс, иначе технологическое отставание от западных и восточных конкурентов, активно внедряющих языковые модели в свой бизнес, будет нарастать.
Источник - CNews


